신장 트리(Spanning Tree)
- Spanning Tree, 또는 신장 트리 라고 불리움 (Spanning Tree가 보다 자연스러워 보임)
- 원래의 그래프의 모든 노드가 연결되어 있으면서 트리의 속성을 만족하는 그래프
- 신장 트리의 조건
- 본래의 그래프의 모든 노드를 포함해야 함
- 모든 노드가 서로 연결
- 트리의 속성을 만족시킴 (사이클이 존재하지 않음)

최소 신장 트리
- Minimum Spanning Tree, MST 라고 불리움
- 가능한 Spanning Tree 중에서, 간선의 가중치 합이 최소인 Spanning Tree를 지칭함
최소 신장 트리를 찾는 알고리즘 여러가지 중
Kruskal’s algorithm (크루스칼 알고리즘), Prim's algorithm (프림 알고리즘) 두가지가 대표적!
일단 첫번재 크루스칼 알고리즘 부터.
크루스칼 알고리즘 (Kruskal's algorithm)
- 모든 정점을 독립적인 집합으로 만든다.
- 모든 간선을 비용을 기준으로 정렬하고, 비용이 작은 간선부터 양 끝의 두 정점을 비교한다.
- 두 정점의 최상위 정점을 확인하고, 서로 다를 경우 두 정점을 연결한다. (최소 신장 트리는 사이클이 없으므로, 사이클이 생기지 않도록 하는 것임)
=> 탐욕 알고리즘을 기초로 하고 있음 (당장 눈 앞의 최소 비용을 선택해서, 결과적으로 최적의 솔루션을 찾음)


그래프 간선 중 가중치가 최저인 것을 선택한다.
매 순간 사이클이 생기지 않으면 가중치가 최저인 것을 선택한다.
알고리즘 구현할 때, 사이클이 생기지 않는 것은 Union-Find 알고리즘을 사용한다.
Union-Find 알고리즘
- Disjoint Set을 표현할 때 사용하는 알고리즘으로 트리 구조를 활용하는 알고리즘
- 간단하게, 노드들 중에 연결된 노드를 찾거나, 노드들을 서로 연결할 때 (합칠 때) 사용
- Disjoint Set이란
- 서로 중복되지 않는 부분 집합들로 나눠진 원소들에 대한 정보를 저장하고 조작하는 자료구조
- 공통 원소가 없는 (서로소) 상호 배타적인 부분 집합들로 나눠진 원소들에 대한 자료구조를 의미함
- Disjoint Set = 서로소 집합 자료구조
=> 서로 중복되지 않는 집합끼리의 연산을 처리하는 알고리즘이다!!
Union : 두 부분 집합을 합치는 연산
Find : 두 부분 집합을 합칠 때 사이클이 있는지 체크하는 연산 => 두 노드가 같은 집합에 속해있는지 체크
- 초기화
- n 개의 원소가 개별 집합으로 이뤄지도록 초기화

- n 개의 원소가 개별 집합으로 이뤄지도록 초기화
- Union
- 두 개별 집합을 하나의 집합으로 합침, 두 트리를 하나의 트리로 만듬

- 두 개별 집합을 하나의 집합으로 합침, 두 트리를 하나의 트리로 만듬
- Find
- 여러 노드가 존재할 때, 두 개의 노드를 선택해서, 현재 두 노드가 서로 같은 그래프에 속하는지 판별하기 위해, 각 그룹의 최상단 원소 (즉, 루트 노드)를 확인

- 여러 노드가 존재할 때, 두 개의 노드를 선택해서, 현재 두 노드가 서로 같은 그래프에 속하는지 판별하기 위해, 각 그룹의 최상단 원소 (즉, 루트 노드)를 확인
Union-Find 알고리즘의 고려할 점
- Union 순서에 따라서, 최악의 경우 링크드 리스트와 같은 형태가 될 수 있음.
- 이 때는 Find/Union 시 계산량이 O(N) 이 될 수 있으므로, 해당 문제를 해결하기 위해, union-by-rank, path compression 기법을 사용함

=> 선택한 노드가 E이고 E의 Root 노드를 찾을 때 시간복잡도가 O(N)이다.
이런 경우를 해결하기 위해 Union-By-Rank 또는 Path Compression 를 사용함!
union-by-rank 기법
- 각 트리에 대해 높이(rank)를 기억해 두고,
- Union시 두 트리의 높이(rank)가 다르면, 높이가 작은 트리를 높이가 큰 트리에 붙임 (즉, 높이가 큰 트리의 루트 노드가 합친 집합의 루트 노드가 되게 함)
- 높이가 h - 1 인 두 개의 트리를 합칠 때는 한 쪽의 트리 높이를 1 증가시켜주고, 다른 쪽의 트리를 해당 트리에 붙여줌
- 초기화시, 모든 원소는 높이(rank) 가 0 인 개별 집합인 상태에서, 하나씩 원소를 합칠 때, union-by-rank 기법을 사용한다면,
- 높이가 h 인 트리가 만들어지려면, 높이가 h - 1 인 두 개의 트리가 합쳐져야 함
- 높이가 h - 1 인 트리를 만들기 위해 최소 n개의 원소가 필요하다면, 높이가 h 인 트리가 만들어지기 위해서는 최소 2n개의 원소가 필요함
- 따라서 union-by-rank 기법을 사용하면, union/find 연산의 시간복잡도는 O(N) 이 아닌, O(logN) 로 낮출 수 있음
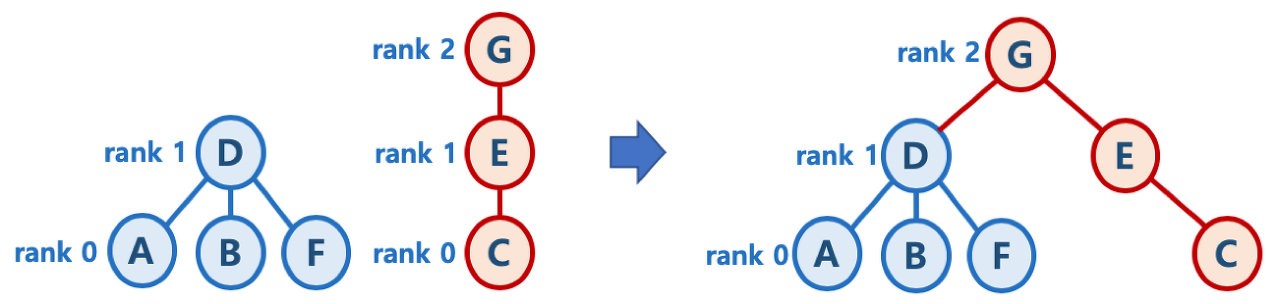
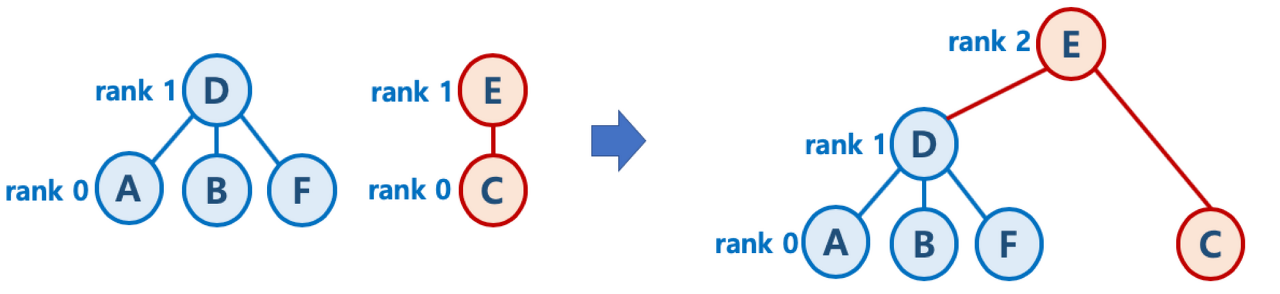
path compression
- Find를 실행한 노드에서 거쳐간 노드를 루트에 다이렉트로 연결하는 기법
- Find를 실행한 노드는 이후부터는 루트 노드를 한번에 알 수 있음


음
무슨말인지 하나도 모르겠다
알듯말듯...
같은부분 계속 반복하면서 들었는뎅..
어쨌든 오늘까지 패스트캠퍼스 30일 미션 챌린지 완성!!!!
추석연휴도 있었고.. 쉬는 날, 퇴사하고 여행간날 많았는데 꾸준히 끝까지 듣다니
성공.. :)
패스트캠퍼스 [직장인 실무교육]
프로그래밍, 영상편집, UX/UI, 마케팅, 데이터 분석, 엑셀강의, The RED, 국비지원, 기업교육, 서비스 제공.
fastcampus.co.kr
본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성되었습니다.
'알고리즘' 카테고리의 다른 글
| [알고리즘] 크루스칼 알고리즘 코드 (0) | 2021.10.08 |
|---|---|
| [알고리즘] 패스트캠퍼스 챌린지 29일차 (0) | 2021.10.04 |
| [알고리즘] 패스트캠퍼스 챌린지 28일차 (0) | 2021.10.03 |
| [알고리즘] 패스트캠퍼스 챌린지 27일차 (0) | 2021.10.02 |
| [알고리즘] 패스트캠퍼스 챌린지 26일차 (0) | 2021.10.01 |



